




3 Database Definition
BEGIN DATA BASE database name;
The database name is from 1 through 6 characters and may consist of uppercase alphabetic characters, the numbers 0 through 9, or the minus sign (-). The name must begin with a letter. This statement must be terminated by a semicolon.
For example:
BEGIN DATA BASE EXAMPL;
DEFAULT LANGUAGE language [@modifier ] ;
For example:
DEFAULT LANGUAGE german@nofold;
PASSWORDS:
It is followed by a list of user-class numbers and their corresponding passwords. Each password definition has the following form:
user-class number password;
Each user-class number, password pair must appear on a new line. The user-class number is an integer from 1 through 31 and must be unique within the password section. Passwords are from 1 through 8 ASCII characters, excluding semicolons, blanks and tabs. If the same password is assigned to multiple user class-numbers, the lowest-numbered class will be used. Lines containing only a user-class number and a semicolon will be ignored.
For example:
PASSWORDS:
31 Clerk;
5 Gum-ball;
10 SECRET;
15 ; <<Not currently assigned
22 %-+ ;
NOTE: The term "Passwords" is a bit misleading here, as passwords are now converted to database specific access groups to which acess privileges to individual tables (data sets) are assigned. The passwords section is included for backwards compatibility. It is recommended to use the DBUTIL utility to maintain database access privileges.NOTE: Passwords defined in a schema text file are always upshifted, i.e. only passwords in uppercase letters can be defined.
ITEMS:
It is followed by a list of all items that are to be used in the database. Up to 1024 data items may be defined in a database. Each item definition has the following form:
item name, [ sub-item count ] specifier [( control no. )];
The item name is from 1 through 15 characters and may consist of uppercase alphabetic characters, the numbers 0 through 9, or the minus sign (-). The name must begin with a letter. Item names must be unique within the item section.
The sub-item count is used to define the array length of compound data items (one dimensional item array). An omitted sub-item count or a sub-item count of 1 specifies a simple item. The sub-item count, if specified, must be an integer 1 or greater.
The specifier is used to declare the item type. Items may be defined to contain numeric data or ASCII string data. The string designator must be followed by the maximum string length. The string length must be even and cannot exceed 4096 characters. The item specifiers are described below.
| Specifier | Type | Description | Range | Item Length * | Max. Sub-item Count ** |
|---|---|---|---|---|---|
| L or R8 | Long(Numeric) | Denotes a 12-digitfloating-point number. | � 9.99999999999E125 through �1.00000000000E-130 | 8 bytes | 512 |
| S or R4 | Short(Numeric) | Denotes a 6-digitfloating-point number. | � 3.40282E+38 through �1.17549E-38 | 4 bytes | 1024 |
| I or I2 | Integer(Numeric) | Denotes a 16-bit integernumber (binary). | +32767 through -32768 | 2 bytes | 2048 |
| D or I4 | DoubleInteger(Numeric) | Denotes a 32-bit integernumber. | +2147483647 through -2147483648 | 4 bytes | 1024 |
| X | String | Denotes an ASCII-characterstring. Must be followed by an integer-character count. | Up to 4096 characters | 1 byte per character | 4096 bytes |
* These numbers are for simple items (sub-item count equal to 1). To compute the item length for compound items, multiply the item length shown by the sub-item count.
** The sub-item count is limited by the maximum record length which is 4096 bytes.
The control number is used for external item formatting and must be an integer from 0 through 127. This number may be retrieved using an Eloquence statement, but is otherwise ignored. The control number is provided for use by application programs. Query, for example, uses the number to determine the format of numeric data and to prevent Query from modifying sensitive data. Refer to the Eloquence Query Manual for more information.
Here is an example item-definition section:
ITEMS:
IN-STOCK, I;
COUNT, D;
COST, S;
TOT-SALE, L;
DESCRIPTION, X30;
MONTH, 12X10; <<12 element array
INDEX ITEMS:or
IITEMS:It is followed by a list of all index items to be used in the database. Each definition has the following format:
iitem name = item name [:length] [,item name ... ];
The iitem name is from 1 to 15 characters in length and can consist of uppercase alphabetic characters, the digits 0 to 9, or the minus sign. The name must begin with a letter. Iitem names must be unique within the item and the iitem section. The item name is the name of an already defined item. The referenced item must not be a compound item. If the referenced item is a string item, it is possible to specify a different significant string length to be used. Up to 7 items can be used to form an iitem. The total index length must not exceed 116 bytes.
Example of an iitem definition section:
ITEMS:
PRODUCT-DESC, X30;
FIRSTNAME, X30;
LASTNAME, X30;
BIRTHDATE, D; # Format YYMMDD
IITEMS:
PRODUCT-MC = PRODUCT-DESC:6;
MATCHCODE = LASTNAME:3, FIRSTNAME:2, BIRTHDATE;
PRODUCT-MC is defined as the first 6 characters taken from PRODUCT-DESC. MATCHCODE is defined as the first 3 bytes taken from LASTNAME, the first 2 bytes from FIRSTNAME, and the BIRTHDATE. NOTE: All index items are stored in separate index tree for the data set. The longer the definition of an index item, the more storage space is required to store the tree. Index items do not require storage space in the entry.
SETS:
It is followed by a list of data set definitions. The END statement may follow the last set defined in the database. Syntax for this statement is as follows:
END.
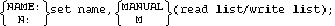
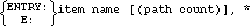
[item name,]
[item name,]
:
:
[item name];
[ iitem name [ collating sequence ]
iitem name [ collating sequence ]
[,iitem name [ collating sequence ] ... ];]

* If the entry is defined with only one item name, the ENTRY line is terminated with a semicolon instead of a comma.
** Capacity is only available for backward compatibility and should be omitted.
Automatic master data sets are defined using the following format:
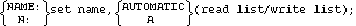
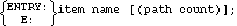
[ iitem name [ collating sequence ]
iitem name [ collating sequence ]
[,iitem name [ collating sequence ] ... ];]

The set name refers to the master data set being defined. The name is from 1 through 15 characters, and may consist of uppercase alphabetic characters, the numbers 0 through 9, or the minus sign (-). The first character must be a letter. All set names must be unique within the schema.
The read list and write list contain user-class numbers separated by commas, and are used to determine which user classes have access to the data set. Specifying a user-class number (an integer from 0 through 31) in the read list allows that user class to have read access to the data set. Specifying a user-class number in the write list allows that user to have read and write access to the data set. The read list may be null, but the write list must contain at least one user-class number.
NOTE: Specifying a user-class number of 0 for read list or write list means read or write access without a password. This is because it is not possible to define a password for a user-class number of 0.
The item name is the name of a data item previously defined in the item-definition section. Each item name must be unique within the data set. A data entry in a manual data set may be defined with up to 1024 item names. A data entry in an automatic data set must contain only one item name. The line containing the last item name in the entry specification must be terminated with a semicolon. The first item appearing in the entry definition is known as the search item. The search item must have a sub-item count of 1 (simple item) and must be no longer than 120 bytes.
The path count specifies the number of paths to be established to detail data sets. Specifying a path count is optional. If specified, it must be an integer from 0 through 16 and must match the detail references. A manual master set with a path count of 0 is known as a stand-alone master set (not associated with a detail data set). For automatic master data sets, the path count is an integer from 1 through 16. Automatic master data sets cannot stand alone.
The iitem name is the name of an index item previously defined in the index item definition section. Each iitem must be unique for this set. All items in an iitem definition must be in the set entry list. The last iitem name must be terminated with a semicolon.
The optional collating sequence controls the order in which string elements in the index are to be sorted. You can specify an index-specific sequence which you may find useful for handling the order of national character-sets correctly. If you don't specify a collating sequence, the DEFAULT LANGUAGE will be used (if defined; otherwise the binary values). The sequence must be installed on your machine and during creation will be stored in database catalog. You can specify a language and a modifier, for example:
... INDEX: MATCHCODE /german@nofold;The maximum-entry count must be an integer from 1 through 232-1. This number historically specified the maximum number of entries to be stored in the data set. It is now optional, and is for information purposes only. No space is reserved in advance. If the number of entries stored in the data set increases beyond this number, it increases accordingly. The value of the maximum-entry count can be determined by using the dbinfo utility. The count will remain at its highest value unless reset with the dbutil utility.
Examples of data set definitions are shown in chapter 6.
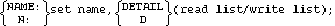
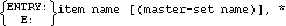
[item name[(master-set name)],]
[item name[(master-set name)],]
:
:
[item name];
[ iitem name [ collating sequence ]
iitem name [ collating sequence ]
[,iitem name [ collating sequence ] ... ];]

* If the entry is defined with only one item name, the ENTRY line is terminated with a semicolon instead of a comma.
** Capacity is only available for backward compatibility and should be omitted.
The set name refers to the detail data set being defined. The name is from 1 through 15 characters and may consist of uppercase alphabetic characters, the numbers 0 through 9, or the minus sign (-). The first character must be a letter. All set names must be unique within the schema.
The read list and write list contain user-class numbers separated by commas and are used to determine which user classes have access to the set. Specifying a user-class number (an integer from 0 through 31) in the read list allows that user class to have read access to the data set. Specifying a user-class number in the write list allows that user to have read and write access to the data set. The read list may be null, but the write list must contain at least one user-class number.
The item name is the name of a data item previously defined in the item-definition section. Each item name must appear on a new line and must be unique within the data set. A data entry may be defined with up to 1024 item names. The line containing the last item name in the entry specification must be terminated with a semicolon.
The master-set name refers to a previously defined master data set. When a master-set name follows an item name, it indicates that the data item is a search item linking the detail data set to the named master set. Up to 16 data paths may be defined. If no data paths are defined in the detail set, the set is known as a stand-alone detail set.
In order for a data path between a master and a detail set to be valid, the search-item type (I, D, S, L, or X) in each data set must be the same. For string items (type X), the string lengths must also be the same. The search-item name in the master data set does not have to match the search-item name in the detail data set. Only simple items (sub-item count equal to 1 or not specified) can be search items. Also, the search item must not be longer than 120 bytes (an ISAM limitation).
The iitem name is the name of an index item previously defined in the index item definition section. Each iitem must be unique for this set. All items in an iitem definition must be in the set entry list. The last iitem name must be terminated with a semicolon.
The collating sequence controls the order in which string elements in the index are to be sorted. You can specify an index-specific sequence which you may find useful for handling the order of national character-sets correctly. If you don't specify a collating sequence, the DEFAULT LANGUAGE will be used (if defined; otherwise the binary values). The sequence must be installed on your machine and during creation will be stored in the database catalog. You can specify a language and a modifier, for example:
... MATCHCODE /german@nofold;The maximum-entry count must be an integer from 1 through 232-1. This count specifies the maximum number of entries to be stored in the set. For examples of data set definitions see "Set Definition" on page 47.