




2 Sort Statements and Functions
WORKFILE IS # file number [ ;THREAD IS
[ set id 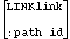 , ... ] set id ] thread list
, ... ] set id ] thread list
(up to 10 sets allowed)
The parameters are:
Some examples of the WORKFILE IS # statement are:
WORKFILE IS#1; THREAD IS"CUSTOMER" WORKFILE IS#X+3; THREAD IS "CUSTOMER":2, "DATE" WORKFILE IS#8; THREAD IS "CUSTOMER":2, "ORDER"Up to 10 data sets can be specified for any thread list. The number of sets in the list is referred to as the thread length. Each set must be related to the sets on either side of it (or one side if it is at the end of the thread) by a path in the data base (or a synthetic path using the LINK option). This defines the hierarchical structure, with the leftmost set in the thread list usually being the highest (usually the least commonly occuring) in the hierarchy. Successful execution of WORKFILE IS # converts the file into a workfile. To convert a file to a workfile, the file must be ASSIGNed in exclusive mode. The file remains a workfile until either another file is assigned in its place (same file number) or it is de-assigned. Closing the data base to which the workfile pertains automatically de-assigns the workfile.
The workfile is used to store all pointers generated by FIND, QFIND and SORT BY operations. Initially, the workfile contains no pointers, so any attempt to access them (via READ #) will result in an error. The REC function returns 0 to indicate this null state. Pointers can be put in the workfile by executing SORT BY, FIND, QFIND, FIND ALL or PRINT #.
The workfile is composed of logical records whose lengths in bytes are 4 times the thread length. Thus, a 4-byte pointer is stored for each set in the thread in any given logical record. Pointers may range in the value from 1 to the capacity of the set to which they pertain. (The first pointer in the record corresponds to the first set in the thread, the second pointer corresponds to the second set, and so on.)
In the case where more than one path connects two adjacent sets in the thread, it is necessary to specify which path is to be used. This is done by suffixing the first of the sets with a ":" and following that with a path id. The path id for a particular path is determined by using the schema listing. To find the path with path id n, for example, scan the detail for the nth occurrence of the master set name. If the path id is not specified, 1 is assumed.
A method exists for defining data set relationships independent of the data base structure. This method is used to link a detail data set to a master data set in the thread list. This is done by using the LINK option, which specifies an item in the detail data set and is used to perform a calculated access into the specified master data set. This item must match the type and length of the search item in the master data set (which is then the set id following the LINK in the thread list).
All SORT BY, FIND and QFIND operations work with the current workfile. Executing another WORKFILE IS # deactivates the current workfile and defines a new one. All subsequent SORTs, QFINDS and FINDs then work on the new file. The information in the old workfile is still intact, however, and can be accessed via READ # and PRINT # statements.
Since it may by desirable to return to do additional FINDs and SORTs on the previous workfile, a method is provided for saving and reactivating a workfile. This is done by executing another WORKFILE IS # which does not include the thread list. This will deactivate (but not erase) the current workfile and allow you to activate an old workfile. Do not attempt to reactivate the workfile by respecifying the thread list, since this loses all information currently in the file by resetting WFLEN to 0.
Expressions are allowed in all WORKFILE IS # parameters. When invoking multiple-line function subprograms, however, these subprograms cannot execute SORT BY, FIND, WORKFILE IS #, IN DATA SET or DBASE IS statements.